Publications
Publications by categories are in reversed chronological order.
2026
- Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVRXiao Liang*, Zhong-Zhi Li*, Yeyun Gong†, Yelong Shen, Ying Nian Wu, Zhijiang Guo†, and Weizhu Chen†In ICLR, 2026
Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a key paradigm for post-training Large Language Models (LLMs), particularly for complex reasoning tasks. However, vanilla RLVR training has been shown to improve Pass@1 performance at the expense of policy entropy, leading to reduced generation diversity and limiting the Pass@k performance, which typically represents the upper bound of LLM reasoning capability. In this paper, we systematically analyze the policy’s generation diversity from the perspective of training problems and find that augmenting and updating training problems helps mitigate entropy collapse during training. Based on these observations, we propose an online Self-play with Variational problem Synthesis (SvS) strategy for RLVR training, which uses the policy’s correct solutions to synthesize variational problems while ensuring their reference answers remain identical to the originals. This self-improving strategy effectively maintains policy entropy during training and substantially improves Pass@k compared with standard RLVR, sustaining prolonged improvements and achieving absolute gains of 18.3% and 22.8% in Pass@32 performance on the competition-level AIME24 and AIME25 benchmarks. Experiments on 12 reasoning benchmarks across varying model sizes from 3B to 32B consistently demonstrate the generalizability and robustness of SvS.
- ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual RecallJiayu Yang*, Yuxuan Fan*, Songning Lai, Shengen Wu, Jiaqi Tang, Chun Kang, Zhijiang Guo†, and Yutao Yue†In ICLR, 2026
Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
- Learning Like Humans: Resource-Efficient Federated Fine-Tuning through Cognitive Developmental StagesYebo Wu*, Jingguang Li*, Zhijiang Guo†, and Li Li†In ICLR, 2026
Federated fine-tuning enables Large Language Models (LLMs) to adapt to downstream tasks while preserving data privacy, but its resource-intensive nature limits deployment on edge devices. In this paper, we introduce Developmental Federated Tuning (DevFT), a resource-efficient approach inspired by cognitive development that progressively builds a powerful LLM from a compact foundation. DevFT decomposes the fine-tuning process into developmental stages, each optimizing submodels with increasing parameter capacity. Knowledge from earlier stages transfers to subsequent submodels, providing optimized initialization parameters that prevent convergence to local minima and accelerate training. This paradigm mirrors human learning, gradually constructing comprehensive knowledge structure while refining existing skills. To efficiently build stage-specific submodels, DevFT introduces deconfliction-guided layer grouping and differential-based layer fusion to distill essential information and construct representative layers. Evaluations across multiple benchmarks demonstrate that DevFT significantly outperforms state-of-the-art methods, achieving up to 4.59 faster convergence, 10.67 reduction in communication overhead, and 9.07% average performance improvement, while maintaining compatibility with existing approaches.
- When Silence Is Golden: Can LLMs Learn to Abstain in Temporal QA and Beyond?Xinyu Zhou, Chang Jin, Carsten Eickhoff, Zhijiang Guo, and Seyed Ali BahrainianIn ICLR, 2026
Large language models (LLMs) rarely admit uncertainty, often producing fluent but misleading answers, rather than abstaining (i.e., refusing to answer). This weakness is even evident in temporal question answering, where models frequently ignore time-sensitive evidence and conflate facts across different time-periods. In this paper, we present the first empirical study of training LLMs with an abstention ability while reasoning about temporal QA. Existing approaches such as calibration might be unreliable in capturing uncertainty in complex reasoning. We instead frame abstention as a teachable skill and introduce a pipeline that couples Chain-of-Thought (CoT) supervision with Reinforcement Learning (RL) guided by abstention-aware rewards. Our goal is to systematically analyze how different information types and training techniques affect temporal reasoning with abstention behavior in LLMs. Through extensive experiments studying various methods, we find that RL yields strong empirical gains on reasoning: a model initialized by Qwen2.5-1.5B-Instruct surpasses GPT-4o by and in Exact Match on TimeQA-Easy and Hard, respectively. Moreover, it improves the True Positive rate on unanswerable questions by over a pure supervised fine-tuned (SFT) variant. Beyond performance, our analysis shows that SFT induces overconfidence and harms reliability, while RL improves prediction accuracy but exhibits similar risks. Finally, by comparing implicit reasoning cues (e.g., original context, temporal sub-context, knowledge graphs) with explicit CoT supervision, we find that implicit information provides limited benefit for reasoning with abstention. Our study provides new insights into how abstention and reasoning can be jointly optimized, providing a foundation for building more reliable LLMs.
- SwingArena: Competitive Programming Arena for Long-context GitHub Issue SolvingWendong Xu, Jing Xiong, Chenyang Zhao, Qiujiang Chen, Haoran Wang, Hui Shen, Zhongwei Wan, Jianbo Dai, Taiqiang Wu, He Xiao, Chaofan Tao, Z. Morley Mao, Ying Sheng, Zhijiang Guo, Hongxia Yang, Bei Yu, Lingpeng Kong, Quanquan Gu, and Ngai WongIn ICLR (Oral), 2026
We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
- A Survey on Federated Fine-Tuning of Large Language ModelsYebo Wu, Chunlin Tian, Jingguang Li, He Sun, Kahou Tam, Zhanting Zhou, Haicheng Liao, Zhijiang Guo†, Li Li†, and Chengzhong XuIn TMLR, 2026
Large Language Models (LLMs) have demonstrated impressive success across various tasks. Integrating LLMs with Federated Learning (FL), a paradigm known as FedLLM, offers a promising avenue for collaborative model adaptation while preserving data privacy. This survey provides a systematic and comprehensive review of FedLLM. We begin by tracing the historical development of both LLMs and FL, summarizing relevant prior research to set the context. Subsequently, we delve into an in-depth analysis of the fundamental challenges inherent in deploying FedLLM. Addressing these challenges often requires efficient adaptation strategies; therefore, we conduct an extensive examination of existing Parameter-Efficient Fine-tuning (PEFT) methods and explore their applicability within the FL framework. To rigorously evaluate the performance of FedLLM, we undertake a thorough review of existing fine-tuning datasets and evaluation benchmarks. Furthermore, we discuss FedLLM’s diverse real-world applications across multiple domains. Finally, we identify critical open challenges and outline promising research directions to foster future advancements in FedLLM. This survey aims to serve as a foundational resource for researchers and practitioners, offering valuable insights into the rapidly evolving landscape of federated fine-tuning for LLMs. It also establishes a roadmap for future innovations in privacy-preserving AI. We actively maintain a GitHub repo \hrefthis https URLthis https URL to track cutting-edge advancements in this field.






2025
- Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive ExplorationZhicheng Yang, Zhijiang Guo, Yinya Huang, Yongxin Wang, Dongchun Xie, Yiwei Wang, Xiaodan Liang, and Jing TangIn ArXiv, 2025
Reinforcement Learning with Verifiable Reward (RLVR) has emerged as a powerful paradigm for unlocking reasoning capabilities in large language models, yet its full potential is hindered by two under-explored dimensions: Depth-the hardest problem a model can sample; Breadth-the number of instances consumed in a single iteration. We dissect the popular GRPO algorithm and reveal a systematic bias: the cumulative-advantage disproportionately weights samples with medium accuracy, while down-weighting the low-accuracy instances that are crucial for pushing reasoning boundaries. To rectify the depth neglect, we introduce Difficulty Adaptive Rollout Sampling (DARS), which re-weights hard problems through targeted multi-stage rollouts, thereby increasing the number of positive rollouts for hard problems. Empirically, naively enlarging rollout size only accelerates convergence and even hurts Pass@K. Our DARS, in contrast, delivers consistent Pass@K gains without extra inference cost at convergence. Just as we adaptively expanded the depth of exploration, we now ask whether aggressively scaling the breadth of training data can further amplify reasoning gains. To this end, we intensely scale batch size and replace PPO’s mini-batch iterations with full-batch updates over multiple epochs. Increasing breadth significantly enhances Pass@1 performance. Large-breadth training sustains high token-level entropy, indicating continued exploration and reduced gradient noise. We further present DARS-B, which augments DARS with large breadth, and demonstrate simultaneous gains in Pass@K and Pass@1. The results confirm that breadth and adaptive exploration across depth operate as orthogonal dimensions in RLVR, which are key to unleashing the reasoning power of RLVR.
- TL; DR: Too Long, Do Re-weighting for Effcient LLM Reasoning CompressionZhong-Zhi Li*, Xiao Liang*, Zihao Tang, Lei Ji, Peijie Wang, Haotian Xu, Haizhen Huang, Weiwei Deng, Ying Nian Wu, Yeyun Gong, Zhijiang Guo†, Xiao Liu†, Fei Yin, and Cheng-Lin LiuIn ArXiv, 2025
Large Language Models (LLMs) have recently achieved remarkable progress by leveraging Reinforcement Learning and extended Chain-of-Thought (CoT) techniques. However, the challenge of performing efficient language reasoning–especially during inference with extremely long outputs–has drawn increasing attention from the research community. In this work, we propose a dynamic ratio-based training pipeline that does not rely on sophisticated data annotations or interpolation between multiple models. We continuously balance the weights between the model’s System-1 and System-2 data to eliminate redundant reasoning processes while preserving the model’s reasoning capability. We validate our approach across models on DeepSeek-R1-Distill-7B and DeepSeek-R1-Distill-14B and on a diverse set of benchmarks with varying difficulty levels. Our method significantly reduces the number of output tokens by nearly 40% while maintaining the accuracy of the reasoning. Our code and data will be available soon.
- TreeRPO: Tree Relative Policy OptimizationZhicheng Yang, Zhijiang Guo, Yinya Huang, Xiaodan Liang, Yiwei Wang, and Jing TangIn ArXiv, 2025
Large Language Models (LLMs) have shown remarkable reasoning capabilities through Reinforcement Learning with Verifiable Rewards (RLVR) methods. However, a key limitation of existing approaches is that rewards defined at the full trajectory level provide insufficient guidance for optimizing the intermediate steps of a reasoning process. To address this, we introduce \textbf\name, a novel method that estimates the mathematical expectations of rewards at various reasoning steps using tree sampling. Unlike prior methods that rely on a separate step reward model, \name directly estimates these rewards through this sampling process. Building on the group-relative reward training mechanism of GRPO, \name innovatively computes rewards based on step-level groups generated during tree sampling. This advancement allows \name to produce fine-grained and dense reward signals, significantly enhancing the learning process and overall performance of LLMs. Experimental results demonstrate that our \name algorithm substantially improves the average Pass@1 accuracy of Qwen-2.5-Math on test benchmarks, increasing it from 19.0% to 35.5%. Furthermore, \name significantly outperforms GRPO by 2.9% in performance while simultaneously reducing the average response length by 18.1%, showcasing its effectiveness and efficiency. Our code will be available at \hrefhttps://github.com/yangzhch6/TreeRPOhttps://github.com/yangzhch6/TreeRPO.
- From System 1 to System 2: A Survey of Reasoning Large Language ModelsZhong-Zhi Li*, Duzhen Zhang*, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo†, Le Song†, and Cheng-Lin Liu†In TPAMI, 2025
Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI’s o1/o3 and DeepSeek’s R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \hrefthis https URLGitHub Repository to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
- Atom of Thoughts for Markov LLM Test-Time ScalingFengwei Teng, Quan Shi, Zhaoyang Yu, Jiayi Zhang, Yuyu Luo, Chenglin Wu†, and Zhijiang Guo†In NeurIPS, 2025
Large Language Models (LLMs) achieve superior performance through training-time scaling, and test-time scaling further enhances their capabilities by conducting effective reasoning during inference. However, as the scale of reasoning increases, existing test-time scaling methods suffer from accumulated historical information, which not only wastes computational resources but also interferes with effective reasoning. To address this issue, we observe that complex reasoning can be achieved by solving a series of independent and self-contained subquestions. These subquestions are essentially \textitatomic questions, exhibiting the memoryless property similar to Markov processes. Based on this observation, we propose Atom of Thoughts (\our), where each state transition consists of decomposing the current question into a dependency-based directed acyclic graph and contracting its subquestions, forming a simplified question that maintains answer equivalence with the original problem. This answer preservation enables the iterative \textitdecomposition-contraction process to naturally form a meaningful Markov reasoning process. Furthermore, these atomic states can be seamlessly integrated into existing test-time scaling methods, enabling \our to serve as a plug-in enhancement for improving reasoning capabilities. Experiments across six benchmarks demonstrate the effectiveness of \our both as a standalone framework and a plug-in enhancement. Notably, on HotpotQA, when applied to gpt-4o-mini, \our achieves an \textbf80.6% F1 score, surpassing o3-mini by \textbf3.4% and DeepSeek-R1 by \textbf10.6%.
- EFFIBENCH-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated CodeYuhao Qing*, Boyu Zhu*, Mingzhe Du*, Zhijiang Guo†, Terry Yue Zhuo, Qianru Zhang, Jie M Zhang, Heming Cui, Siu-Ming Yiu, Dong Huang†, See-Kiong Ng, and Luu Anh TuanIn NeurIPS, 2025
Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf62% of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1’s Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
- AVERIMATEC: A Dataset for Automatic Verification of Image-Text Claims with Evidence from the WebRui Cao, Zifeng Ding, Zhijiang Guo, Michael Schlichtkrull, and Andreas VlachosIn NeurIPS, 2025
Textual claims are often accompanied by images to enhance their credibility and spread on social media and but this also raises concerns about the spread of misinformation. Existing datasets for automated verification of image-text claims remain limited and as they often consist of synthetic claims and lack evidence annotations to capture the reasoning behind the verdict. In this work and we introduce AVerImaTeC and a dataset consisting of 1,297 real-world image-text claims. Each claim is annotated with question-answer (QA) pairs containing evidence from the web and reflecting a decomposed reasoning regarding the verdict. We mitigate common challenges in fact-checking datasets such as contextual dependence and temporal leakage and and evidence insufficiency and via claim normalization and temporally constrained evidence annotation and and a two-stage sufficiency check. We assess the consistency of the annotation in AVerImaTeC via inter-annotator studies and achieving a κ=0.742 on verdicts and 74.7% consistency on QA pairs. We also propose a novel evaluation method for evidence retrieval and conduct extensive experiments to establish baselines for verifying image-text claims using open-web evidence.
- Activation-Guided Consensus Merging for Large Language ModelsYuxuan Yao, Shuqi Liu, Zehua Liu, Qintong Li, Mingyang Liu, Xiongwei Han, Zhijiang Guo, Han Wu, and Linqi SongIn NeurIPS, 2025
Recent research has increasingly focused on reconciling the reasoning capabilities of System 2 with the efficiency of System 1. While existing training-based and prompt-based approaches face significant challenges in terms of efficiency and stability, model merging emerges as a promising strategy to integrate the diverse capabilities of different Large Language Models (LLMs) into a unified model. However, conventional model merging methods often assume uniform importance across layers, overlooking the functional heterogeneity inherent in neural components. To address this limitation, we propose \textbfActivation-Guided \textbfConsensus \textbfMerging (\textbfACM), a plug-and-play merging framework that determines layer-specific merging coefficients based on mutual information between activations of pre-trained and fine-tuned models. ACM effectively preserves task-specific capabilities without requiring gradient computations or additional training. Extensive experiments on Long-to-Short (L2S) and general merging tasks demonstrate that ACM consistently outperforms all baseline methods. For instance, in the case of Qwen-7B models, TIES-Merging equipped with ACM achieves a \textbf55.3% reduction in response length while simultaneously improving reasoning accuracy by \textbf1.3 points.
- TIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World ScenariosShaohang Wei, Wei Li, Feifan Song, Wen Luo, Tianyi Zhuang, Haochen Tan, Zhijiang Guo, and Houfeng WangIn NeurIPS (Spotlight), 2025
Temporal reasoning is pivotal for Large Language Models (LLMs) to comprehend the real world. However, existing works neglect the real-world challenges for temporal reasoning: (1) intensive temporal information, (2) fast-changing event dynamics, and (3) complex temporal dependencies in social interactions. To bridge this gap, we propose a multi-level benchmark TIME, designed for temporal reasoning in real-world scenarios. TIME consists of 38,522 QA pairs, covering 3 levels with 11 fine-grained sub-tasks. This benchmark encompasses 3 sub-datasets reflecting different real-world challenges: TIME-Wiki, TIME-News, and TIME-Dial. We conduct extensive experiments on reasoning models and non-reasoning models. And we conducted an in-depth analysis of temporal reasoning performance across diverse real-world scenarios and tasks, and summarized the impact of test-time scaling on temporal reasoning capabilities. Additionally, we release TIME-Lite, a human-annotated subset to foster future research and standardized evaluation in temporal reasoning.
- FaStFACT: Faster, Stronger Long-Form Factuality Evaluations in LLMsYingjia Wan, Haochen Tan, Xiao Zhu, Xinyu Zhou, Zhiwei Li, Qingsong Lv, Changxuan Sun, Jiaqi Zeng, Yi Xu, Jianqiao Lu, Yinhong Liu†, and Zhijiang Guo†In Findings of EMNLP, 2025
Evaluating the factuality of long-form generations from Large Language Models (LLMs) remains challenging due to accuracy issues and costly human assessment. Prior efforts attempt this by decomposing text into claims, searching for evidence, and verifying claims, but suffer from critical drawbacks: (1) inefficiency due to complex pipeline components unsuitable for long LLM outputs, and (2) ineffectiveness stemming from inaccurate claim sets and insufficient evidence collection of one-line snippets.To address these limitations, we propose \name, a fast and strong evaluation framework that achieves the highest alignment with human evaluation and efficiency among existing baselines. \name first employs chunk-level claim extraction integrated with confidence-based pre-verification, significantly reducing the cost of web searching and inference calling while ensuring reliability. For searching and verification, it collects document-level evidence from crawled webpages and selectively retrieves it during verification, addressing the evidence insufficiency problem in previous pipelines.Extensive experiments based on an aggregated and manually annotated benchmark demonstrate the reliability of \name in both efficiently and effectively evaluating the factuality of long-form LLM generations.
- When Inverse Data Outperforms: Exploring the Pitfalls of Mixed Data in Multi-Stage Fine-TuningMengyi Deng, Xin Li, Tingyu Zhu, Zhicheng Yang, Zhijiang Guo†, and Wei Wang†In Findings of EMNLP, 2025
Existing work has shown that o1-level performance can be achieved with limited data distillation, but most existing methods focus on unidirectional supervised fine-tuning (SFT), overlooking the intricate interplay between diverse reasoning patterns. In this paper, we construct r1k, a high-quality reverse reasoning dataset derived by inverting 1,000 forward examples from s1k, and examine how SFT and Direct Preference Optimization (DPO) affect alignment under bidirectional reasoning objectives. SFT on r1k yields a 1.6%–6.8% accuracy improvement over s1k across evaluated benchmarks. However, naively mixing forward and reverse data during SFT weakens the directional distinction. Although DPO can partially recover this distinction, it also suppresses less preferred reasoning paths by shifting the probability mass toward irrelevant outputs. These findings suggest that mixed reasoning data introduce conflicting supervision signals, underscoring the need for robust and direction-aware alignment strategies.
- TreeReview: A Dynamic Tree of Questions Framework for Deep and Efficient LLM-based Scientific Peer ReviewYuan Chang*, Ziyue Li*, Hengyuan Zhang†, Yuanbo Kong, Yanru Wu, Zhijiang Guo†, and Ngai Wong†In EMNLP, 2025
While Large Language Models (LLMs) have shown significant potential in assisting peer review, current methods often struggle to generate thorough and insightful reviews while maintaining efficiency. In this paper, we propose TreeReview, a novel framework that models paper review as a hierarchical and bidirectional question-answering process. TreeReview first constructs a tree of review questions by recursively decomposing high-level questions into fine-grained sub-questions and then resolves the question tree by iteratively aggregating answers from leaf to root to get the final review. Crucially, we incorporate a dynamic question expansion mechanism to enable deeper probing by generating follow-up questions when needed. We construct a benchmark derived from ICLR and NeurIPS venues to evaluate our method on full review generation and actionable feedback comments generation tasks. Experimental results of both LLM-based and human evaluation show that TreeReview outperforms strong baselines in providing comprehensive, in-depth, and expert-aligned review feedback, while reducing LLM token usage by up to 80% compared to computationally intensive approaches. Our code and benchmark dataset are available at https://github.com/YuanChang98/tree-review.
- ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific ChartsRuiran Su, Jiasheng Si, Zhijiang Guo, and Janet B PierrehumbertIn EMNLP, 2025
Scientific fact-checking has mostly focused on text and tables, overlooking scientific charts, which are key for presenting quantitative evidence and statistical reasoning. We introduce ClimateViz, the first large-scale benchmark for scientific fact-checking using expert-curated scientific charts. ClimateViz contains 49,862 claims linked to 2,896 visualizations, each labeled as support, refute, or not enough information. To improve interpretability, each example includes structured knowledge graph explanations covering trends, comparisons, and causal relations. We evaluate state-of-the-art multimodal language models, including both proprietary and open-source systems, in zero-shot and few-shot settings. Results show that current models struggle with chart-based reasoning: even the best systems, such as Gemini 2.5 and InternVL 2.5, reach only 76.2 to 77.8 percent accuracy in label-only settings, far below human performance (89.3 and 92.7 percent). Explanation-augmented outputs improve performance in some models. We released our dataset and code alongside the paper.
- UNComp: Uncertainty-Aware Long-Context Compressor for Efficient Large Language Model InferenceJing Xiong, Jianghan Shen, Fanghua Ye, Chaofan Tao, Zhongwei Wan, Jianqiao Lu, Xun Wu, Chuanyang Zheng, Zhijiang Guo, Lingpeng Kong, and Ngai WongIn EMNLP, 2025
Deploying large language models (LLMs) is challenging due to their high memory and computational demands, especially during long-context inference. While key-value (KV) caching accelerates inference by reusing previously computed keys and values, it also introduces significant memory overhead. Existing KV cache compression methods such as eviction and merging typically compress the KV cache after it is generated and overlook the eviction of hidden states, failing to improve the speed of the prefilling stage. Additionally, applying a uniform compression rate across different attention heads can harm crucial retrieval heads in needle-in-a-haystack tasks due to excessive compression. In this paper, we propose UNComp, an uncertainty-aware compression scheme that leverages matrix entropy to estimate model uncertainty across layers and heads at the token sequence level. By grouping layers and heads based on their uncertainty, UNComp adaptively compresses both the hidden states and the KV cache. Our method achieves a 1.6x speedup in the prefilling stage and reduces the KV cache to 4.74% of its original size, resulting in a 6.4x increase in throughput and a 1.4x speedup in inference with only a 1.41% performance loss. Remarkably, in needle-in-a-haystack tasks, UNComp outperforms the full-size KV cache even when compressed to 9.38% of its original size. Our approach offers an efficient, training-free Grouped-Query Attention paradigm that can be seamlessly integrated into existing KV cache schemes.
- Aligning with Logic: Measuring, Evaluating and Improving Logical Consistency in Large Language ModelsYinhong Liu, Zhijiang Guo, Tianya Liang, Ehsan Shareghi, Ivan Vuli’c, and Nigel CollierIn ICML (Spotlight), 2025
Recent research in Large Language Models (LLMs) has shown promising progress related to LLM alignment with human preferences. LLM-empowered decision-making systems are expected to be predictable, reliable and trustworthy, which implies being free from paradoxes or contradictions that could undermine their credibility and validity. However, LLMs still exhibit inconsistent and biased behaviour when making decisions or judgements. In this work, we focus on studying logical consistency of LLMs as a prerequisite for more reliable and trustworthy systems. Logical consistency ensures that decisions are based on a stable and coherent understanding of the problem, reducing the risk of erratic or contradictory outputs. We first propose a universal framework to quantify the logical consistency via three fundamental proxies: transitivity, commutativity and negation invariance. We then evaluate logical consistency, using the defined measures, of a wide range of LLMs, demonstrating that it can serve as a strong proxy for overall robustness. Additionally, we introduce a data refinement and augmentation technique that enhances the logical consistency of LLMs without sacrificing alignment to human preferences. It augments noisy and sparse pairwise-comparison annotations by estimating a partially or totally ordered preference rankings using rank aggregation methods. Finally, we show that logical consistency impacts the performance of LLM-based logic-dependent algorithms, where LLMs serve as logical operators.
- Effi-Code: Unleashing Code Efficiency in Language ModelsDong Huang*, Guangtao Zeng*, Jianbo Dai, Meng Luo, Han Weng, Yuhao Qing, Heming Cui, Zhijiang Guo†, and Jie M. ZhangIn ICML, 2025
As the use of large language models (LLMs) for code generation becomes more prevalent in software development, it is critical to enhance both the efficiency and correctness of the generated code. Existing methods and models primarily focus on the correctness of LLM-generated code, ignoring efficiency. In this work, we present Effi-Code, an approach to enhancing code generation in LLMs that can improve both efficiency and correctness. We introduce a Self-Optimization process based on Overhead Profiling that leverages open-source LLMs to generate a high-quality dataset of correct and efficient code samples. This dataset is then used to fine-tune various LLMs. Our method involves the iterative refinement of generated code, guided by runtime performance metrics and correctness checks. Extensive experiments demonstrate that models fine-tuned on the Effi-Code show significant improvements in both code correctness and efficiency across task types. For example, the pass@1 of DeepSeek-Coder-6.7B-Instruct generated code increases from \textbf43.3% to \textbf76.8%, and the average execution time for the same correct tasks decreases by \textbf30.5%. Effi-Code offers a scalable and generalizable approach to improving code generation in AI systems, with potential applications in software development, algorithm design, and computational problem-solving.
- FormalAlign: Automated Alignment Evaluation for AutoformalizationJianqiao Lu*, Yingjia Wan*, Yinya Huang, Jing Xiong, Zhengying Liu, and Zhijiang Guo†In ICLR, 2025
Autoformalization aims to convert informal mathematical proofs into machine-verifiable formats, bridging the gap between natural and formal languages. However, ensuring semantic alignment between the informal and formalized statements remains challenging. Existing approaches heavily rely on manual verification, hindering scalability. To address this, we introduce \textscFormalAlign, the first automated framework designed for evaluating the alignment between natural and formal languages in autoformalization. \textscFormalAlign trains on both the autoformalization sequence generation task and the representational alignment between input and output, employing a dual loss that combines a pair of mutually enhancing autoformalization and alignment tasks. Evaluated across four benchmarks augmented by our proposed misalignment strategies, \textscFormalAlign demonstrates superior performance. In our experiments, \textscFormalAlign outperforms GPT-4, achieving an Alignment-Selection Score 11.58% higher on \forml-Basic (99.21% vs. 88.91%) and 3.19% higher on MiniF2F-Valid (66.39% vs. 64.34%). This effective alignment evaluation significantly reduces the need for manual verification.
- Determine-Then-Ensemble: Necessity of Top-k Union for Large Language Model EnsemblingYuxuan Yao, Han Wu†, Mingyang Liu, Sichun Luo, Xiongwei Han, Jie Liu, Zhijiang Guo, and Linqi Song†In ICLR (Spotlight), 2025
Large language models (LLMs) exhibit varying strengths and weaknesses across different tasks, prompting recent studies to explore the benefits of ensembling models to leverage their complementary advantages. However, existing LLM ensembling methods often overlook model compatibility and struggle with inefficient alignment of probabilities across the entire vocabulary. In this study, we empirically investigate the factors influencing ensemble performance, identifying model performance, vocabulary size, and response style as key determinants, revealing that compatibility among models is essential for effective ensembling. This analysis leads to the development of a simple yet effective model selection strategy that identifies compatible models. Additionally, we introduce the \textscUnion \textscTop-k \textscEnsembling (\textscUniTE), a novel approach that efficiently combines models by focusing on the union of the top-k tokens from each model, thereby avoiding the need for full vocabulary alignment and reducing computational overhead. Extensive evaluations across multiple benchmarks demonstrate that \textscUniTE significantly enhances performance compared to existing methods, offering a more efficient framework for LLM ensembling.
- OptiBench Meets ReSocratic: Measure and Improve LLMs for Optimization ModelingZhicheng Yang, Yinya Huang, Zhijiang Guo, Wei Shi, Liang Feng, Linqi Song, Yiwei Wang, Xiaodan Liang, and Jing TangIn ICLR, 2025
Large language models (LLMs) have exhibited their problem-solving abilities in mathematical reasoning. Solving realistic optimization (OPT) problems in application scenarios requires advanced and applied mathematics ability. However, current OPT benchmarks that merely solve linear programming are far from complex realistic situations. In this work, we propose OptiBench, a benchmark for End-to-end optimization problem-solving with human-readable inputs and outputs. OptiBench contains rich optimization problems, including linear and nonlinear programming with or without tabular data, which can comprehensively evaluate LLMs’ solving ability. In our benchmark, LLMs are required to call a code solver to provide precise numerical answers. Furthermore, to alleviate the data scarcity for optimization problems, and to bridge the gap between open-source LLMs on a small scale (e.g., Llama-3-8b) and closed-source LLMs (e.g., GPT-4), we further propose a data synthesis method namely ReSocratic. Unlike general data synthesis methods that proceed from questions to answers, \ReSocratic first incrementally synthesizes formatted optimization demonstration with mathematical formulations step by step and then back-translates the generated demonstrations into questions. Based on this, we synthesize the ReSocratic-29k dataset. We further conduct supervised fine-tuning with ReSocratic-29k on multiple open-source models. Experimental results show that ReSocratic-29k significantly improves the performance of open-source models.
- DebateQA: Evaluating Question Answering on Debatable KnowledgeRongwu Xu*, Xuan Qi*, Zehan Qi, Wei Xu, and Zhijiang GuoIn Findings of EACL, 2025
The rise of large language models (LLMs) has enabled us to seek answers to inherently debatable questions on LLM chatbots, necessitating a reliable way to evaluate their ability. However, traditional QA benchmarks assume fixed answers are inadequate for this purpose. To address this, we introduce DebateQA, a dataset of 2,941 debatable questions, each accompanied by multiple human-annotated partial answers that capture a variety of perspectives. We develop two metrics: Perspective Diversity, which evaluates the comprehensiveness of perspectives, and Dispute Awareness, which assesses if the LLM acknowledges the question’s debatable nature. Experiments demonstrate that both metrics align with human preferences and are stable across different underlying models. Using DebateQA with two metrics, we assess 12 popular LLMs and retrieval-augmented generation methods. Our findings reveal that while LLMs generally excel at recognizing debatable issues, their ability to provide comprehensive answers encompassing diverse perspectives varies considerably.
- CtrlA: Adaptive Retrieval-Augmented Generation via Inherent ControlHuanshuo Liu*, Hao Zhang*, Zhijiang Guo†, Kuicai Dong, Xiangyang Li, Yi Quan Lee, Cong Zhang, and Yong LiuIn Findings of ACL, 2025
Retrieval-augmented generation (RAG) has emerged as a promising solution for mitigating hallucinations of large language models (LLMs) with retrieved external knowledge. Adaptive RAG enhances this approach by enabling dynamic retrieval during generation, activating retrieval only when the query exceeds LLM’s internal knowledge. Existing methods primarily focus on detecting LLM’s confidence via statistical uncertainty. Instead, we present the first attempts to solve adaptive RAG from a representation perspective and develop an inherent control-based framework, termed \name. Specifically, we extract the features that represent the honesty and confidence directions of LLM and adopt them to control LLM behavior and guide retrieval timing decisions. We also design a simple yet effective query formulation strategy to support adaptive retrieval. Experiments show that \name is superior to existing adaptive RAG methods on a diverse set of tasks, the honesty steering can effectively make LLMs more honest and confidence monitoring is a promising indicator of retrieval
- AACL
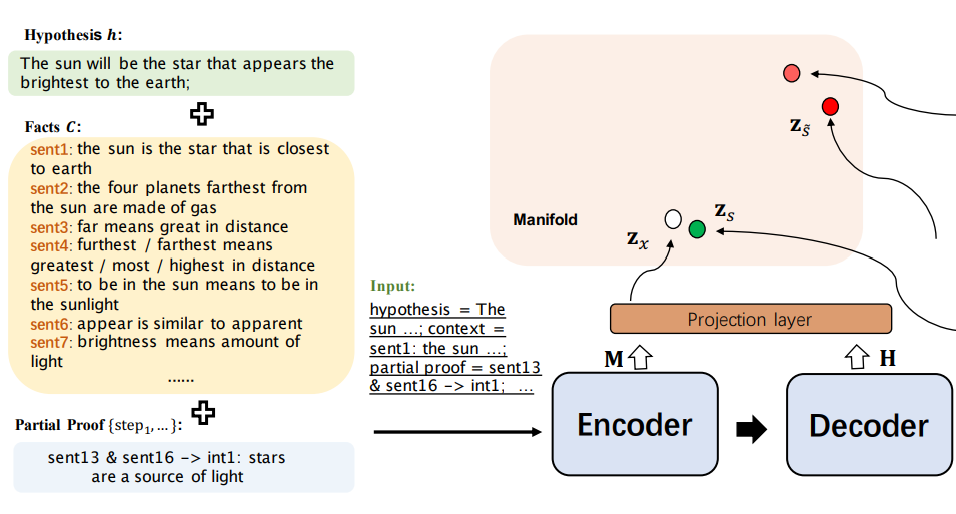 Are LLMs Rigorous Logical Reasoner? Empowering Natural Language Proof Generation with Contrastive Stepwise DecodingYing Su, Xiaojin Fu, Mingwen Liu, and Zhijiang GuoIn AACL, 2025
Are LLMs Rigorous Logical Reasoner? Empowering Natural Language Proof Generation with Contrastive Stepwise DecodingYing Su, Xiaojin Fu, Mingwen Liu, and Zhijiang GuoIn AACL, 2025Logical reasoning remains a pivotal component within the realm of artificial intelligence. The recent evolution of large language models (LLMs) has marked significant progress in this domain. The adoption of strategies like chain-of-thought (CoT) has enhanced the performance of LLMs across diverse reasoning tasks. Nonetheless, logical reasoning that involves proof planning, specifically those that necessitate the validation of explanation accuracy, continues to present stumbling blocks. In this study, we first evaluate the efficacy of LLMs with advanced CoT strategies concerning such tasks. Our analysis reveals that LLMs still struggle to navigate complex reasoning chains, which demand the meticulous linkage of premises to derive a cogent conclusion. To address this issue, we finetune a smaller-scale language model, equipping it to decompose proof objectives into more manageable subgoals. We also introduce contrastive decoding to stepwise proof generation, making use of negative reasoning paths to strengthen the model’s capacity for logical deduction. Experiments on EntailmentBank underscore the success of our method in augmenting the proof planning abilities of language models.
- Analysis of longitudinal social media for monitoring symptoms during a pandemicShixu Lin, Lucas Garay, Yining Hua, Zhijiang Guo, Wanxin Li, Minghui Li, Yujie Zhang, Xiaolin Xu, and Jie YangIn Journal of Biomedical Informatics, 2025
Current studies leveraging social media data for disease monitoring face challenges like noisy colloquial language and insufficient tracking of user disease progression in longitudinal data settings. This study aims to develop a pipeline for collecting, cleaning, and analyzing large-scale longitudinal social media data for disease monitoring, with a focus on COVID-19 pandemic.
- RedStar: Does Scaling Long-CoT Data Unlock Better Slow-Reasoning Systems?Haotian Xu, Xing Wu, Weinong Wang, Zhongzhi Li, Da Zheng, Boyuan Chen, Yi Hu, Shijia Kang, Jiaming Ji, Yingying Zhang, Zhijiang Guo, Yaodong Yang, Muhan Zhang, and Debing ZhangIn ArXiv, 2025
Can scaling transform reasoning? In this work, we explore the untapped potential of scaling Long Chain-of-Thought (Long-CoT) data to 1000k samples, pioneering the development of a slow-thinking model, RedStar. Through extensive experiments with various LLMs and different sizes, we uncover the ingredients for specialization and scale for Long-CoT training. Surprisingly, even smaller models show significant performance gains with limited data, revealing the sample efficiency of Long-CoT and the critical role of sample difficulty in the learning process. Our findings demonstrate that Long-CoT reasoning can be effectively triggered with just a few thousand examples, while larger models achieve unparalleled improvements. We also introduce reinforcement learning (RL)-scale training as a promising direction for advancing slow-thinking systems. RedStar shines across domains: on the MATH-Hard benchmark, RedStar-code-math boosts performance from 66.2% to 81.6%, and on the USA Math Olympiad (AIME), it solves 46.7% of problems using only 21k mixed-code-math datasets. In multimodal tasks like GeoQA and MathVista-GEO, RedStar-Geo achieves competitive results with minimal Long-CoT data, outperforming other slow-thinking systems like QvQ-Preview. Compared to QwQ, RedStar strikes the perfect balance between reasoning and generalizability. Our work highlights that, with careful tuning, scaling Long-CoT can unlock extraordinary reasoning capabilities-even with limited dataset and set a new standard for slow-thinking models across diverse challenges.
- CiteCheck: Towards Accurate Citation Faithfulness DetectionZiyao Xu, Shaohang Wei, Zhuoheng Han, Jing Jin, Zhe Yang, Xiaoguang Li, Haochen Tan, Zhijiang Guo, and Houfeng WangIn ArXiv, 2025
Citation faithfulness detection is critical for enhancing retrieval-augmented generation (RAG) systems, yet large-scale Chinese datasets for this task are scarce. Existing methods face prohibitive costs due to the need for manually annotated negative samples. To address this, we introduce the first large-scale Chinese dataset CiteCheck for citation faithfulness detection, constructed via a cost-effective approach using two-stage manual annotation. This method balances positive and negative samples while significantly reducing annotation expenses. CiteCheck comprises training and test splits. Experiments demonstrate that: (1) the test samples are highly challenging, with even state-of-the-art LLMs failing to achieve high accuracy; and (2) training data augmented with LLM-generated negative samples enables smaller models to attain strong performance using parameter-efficient fine-tuning. CiteCheck provides a robust foundation for advancing citation faithfulness detection in Chinese RAG systems. The dataset is publicly available to facilitate research.

























2024
- Process-Driven Autoformalization in Lean 4Jianqiao Lu*, Yingjia Wan*, Zhengying Liu, Yinya Huang, Jing Xiong, Chengwu Liu, Jianhao Shen, Hui Jin, Jipeng Zhang, Haiming Wang, Zhicheng Yang, Jing Tang, and Zhijiang Guo†In ArXiv, 2024
Autoformalization, the conversion of natural language mathematics into formal languages, offers significant potential for advancing mathematical reasoning. However, existing efforts are limited to formal languages with substantial online corpora and struggle to keep pace with rapidly evolving languages like Lean 4. To bridge this gap, we propose a new benchmark \textbfFormalization for \textbfLean \textbf4 (\textbf\name) designed to evaluate the autoformalization capabilities of large language models (LLMs). This benchmark encompasses a comprehensive assessment of questions, answers, formal statements, and proofs. Additionally, we introduce a \textbfProcess-\textbfSupervised \textbfVerifier (\textbfPSV) model that leverages the precise feedback from Lean 4 compilers to enhance autoformalization. Our experiments demonstrate that the PSV method improves autoformalization, enabling higher accuracy using less filtered training data. Furthermore, when fine-tuned with data containing detailed process information, PSV can leverage the data more effectively, leading to more significant improvements in autoformalization for Lean 4.
- MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code GenerationJianbo Dai*, Jianqiao Lu*, Yunlong Feng, Dong Huang, Guangtao Zeng, Rongju Ruan, Ming Cheng, Haochen Tan†, and Zhijiang Guo†In ArXiv, 2024
Recent advancements in large language models (LLMs) have greatly improved code generation, specifically at the function level. For instance, GPT-4o has achieved a 91.0% pass rate on HumanEval. However, this draws into question the adequacy of existing benchmarks in thoroughly assessing function-level code generation capabilities. Our study analyzed two common benchmarks, HumanEval and MBPP, and found that these might not thoroughly evaluate LLMs’ code generation capacities due to limitations in quality, difficulty, and granularity. To resolve this, we introduce the Mostly Hard Python Problems (MHPP) dataset, consisting of 210 unique human-curated problems. By focusing on the combination of natural language and code reasoning, MHPP gauges LLMs’ abilities to comprehend specifications and restrictions, engage in multi-step reasoning, and apply coding knowledge effectively. Initial evaluations of 26 LLMs using MHPP showed many high-performing models on HumanEval failed to achieve similar success on MHPP. Moreover, MHPP highlighted various previously undiscovered limitations within various LLMs, leading us to believe that it could pave the way for a better understanding of LLMs’ capabilities and limitations.
- AutoPSV: Automated Process-Supervised VerifierJianqiao Lu, Zhiyang Dou, Hongru Wang, Zeyu Cao, Jianbo Dai, Yingjia Wan, Yinya Huang, and Zhijiang Guo†In NeurIPS, 2024
In this work, we propose a novel method named Automated Process-Supervised Verifier (AutoPSV) to enhance the reasoning capabilities of large language models (LLMs) by automatically annotating the reasoning steps. AutoPSV begins by training a verification model on the correctness of final answers, enabling it to generate automatic process annotations. This verification model assigns a confidence score to each reasoning step, indicating the probability of arriving at the correct final answer from that point onward. We detect relative changes in the verification’s confidence scores across reasoning steps to automatically annotate the reasoning process, enabling error detection even in scenarios where ground truth answers are unavailable. This alleviates the need for numerous manual annotations or the high computational costs associated with model-induced annotation approaches. We experimentally validate that the step-level confidence changes learned by the verification model trained on the final answer correctness can effectively identify errors in the reasoning steps. We demonstrate that the verification model, when trained on process annotations generated by AutoPSV, exhibits improved performance in selecting correct answers from multiple LLM-generated outputs. Notably, we achieve substantial improvements across five datasets in mathematics and commonsense reasoning. The source code of AutoPSV is available at https://github.com/rookie-joe/AutoPSV.
- MR-Ben: A Meta-Reasoning Benchmark for Evaluating System-2 Thinking in LLMsZhongshen Zeng, Yinhong Liu, Yingjia Wan, Jingyao Li, Pengguang Chen, Jianbo Dai, Yuxuan Yao, Rongwu Xu, Zehan Qi, Wanru Zhao, Linling Shen, Jianqiao Lu, Haochen Tan, Yukang Chen, Hao Zhang, Zhan Shi, Bailin Wang, Zhijiang Guo†, and Jiaya Jia†In NeurIPS, 2024
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark Mr-Ben that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. Mr-Ben is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
- HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-TuningChunlin Tian*, Zhan Shi*, Zhijiang Guo, Li Li, and Chengzhong XuIn NeurIPS (Oral), 2024
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases.
- EffiLearner: Enhancing Efficiency of Generated Code via Self-OptimizationDong Huang*, Jianbo Dai*, Han Weng, Puzhen Wu, Yuhao Qing, Heming Cui, Zhijiang Guo†, and Jie M.ZhangIn NeurIPS, 2024
Large language models (LLMs) have shown remarkable progress in code generation, but their generated code often suffers from inefficiency, resulting in longer execution times and higher memory consumption. To address this issue, we propose \textbfEffiLearner, a self-optimization framework that utilizes execution overhead profiles to improve the efficiency of LLM-generated code. EffiLearner first generates code using an LLM, then executes it locally to capture execution time and memory usage profiles. These profiles are fed back to the LLM, which then revises the code to reduce overhead. To evaluate the effectiveness of EffiLearner, we conduct extensive experiments on the EffiBench, HumanEval, and MBPP with 16 open-source and 6 closed-source models. Our evaluation results demonstrate that through iterative self-optimization, EffiLearner significantly enhances the efficiency of LLM-generated code. For example, the execution time (ET) of StarCoder2-15B for the EffiBench decreases from 0.93 (s) to 0.12 (s) which reduces 87.1% the execution time requirement compared with the initial code. The total memory usage (TMU) of StarCoder2-15B also decreases from 22.02 (Mb*s) to 2.03 (Mb*s), which decreases 90.8% of total memory consumption during the execution process.
- Knowledge Conflicts for LLMs: A SurveyRongwu Xu*, Zehan Qi*, Zhijiang Guo†, Cunxiang Wang, Hongru Wang, Yue Zhang†, and Wei Xu†In EMNLP, 2024
This survey provides an in-depth analysis of knowledge conflicts for large language models (LLMs), highlighting the complex challenges they encounter when blending contextual and parametric knowledge. Our focus is on three categories of knowledge conflicts: context-memory, inter-context, and intra-memory conflict. These conflicts can significantly impact the trustworthiness and performance of LLMs, especially in real-world applications where noise and misinformation are common. By categorizing these conflicts, exploring the causes, examining the behaviors of LLMs under such conflicts, and reviewing available solutions, this survey aims to shed light on strategies for improving the robustness of LLMs, thereby serving as a valuable resource for advancing research in this evolving area.
- DvD: Dynamic Contrastive Decoding for Knowledge Amplification in Multi-Document Question AnsweringJing Jin, Houfeng Wang, Hao Zhang, Xiaoguang Li, and Zhijiang GuoIn EMNLP, 2024
Large language models (LLMs) are widely used in question-answering (QA) systems but often generate information with hallucinations. Retrieval-augmented generation (RAG) offers a potential remedy, yet the uneven retrieval quality and irrelevant contents may distract LLMs.In this work, we address these issues at the generation phase by treating RAG as a multi-document QA task.We propose a novel decoding strategy, Dynamic Contrastive Decoding, which dynamically amplifies knowledge from selected documents during the generation phase. involves constructing inputs batchwise, designing new selection criteria to identify documents worth amplifying, and applying contrastive decoding with a specialized weight calculation to adjust the final logits used for sampling answer tokens. Zero-shot experimental results on ALCE-ASQA, NQ, TQA and PopQA benchmarks show that our method outperforms other decoding strategies. Additionally, we conduct experiments to validate the effectiveness of our selection criteria, weight calculation, and general multi-document scenarios. Our method requires no training and can be integrated with other methods to improve the RAG performance.
- Do We Need Language-Specific Fact-Checking Models? The Case of ChineseCaiqi Zhang, Zhijiang Guo, and Andreas VlachosIn EMNLP, 2024
This paper investigates the potential benefits of language-specific fact-checking models, focusing on the case of Chinese. We first demonstrate the limitations of translation-based methods and multilingual large language models (e.g., GPT-4), highlighting the need for language-specific systems. We further propose a Chinese fact-checking system that can better retrieve evidence from a document by incorporating context information. To better analyze token-level biases in different systems, we construct an adversarial dataset based on the CHEF dataset, where each instance has large word overlap with the original one but holds the opposite veracity label. Experimental results on the CHEF dataset and our adversarial dataset show that our proposed method outperforms translation-based methods and multilingual LLMs and is more robust toward biases, while there is still large room for improvement, emphasizing the importance of language-specific fact-checking systems.
- Long^2RAG: Evaluating Long-Context&Long-Form Retrieval-Augmented Generation with Key Point RecallZehan Qi*, Rongwu Xu*, Zhijiang Guo†, Cunxiang Wang, Hao Zhang, and Wei Xu†In Findings of EMNLP, 2024
Retrieval-augmented generation (RAG) is a promising approach to address the limitations of fixed knowledge in large language models (LLMs). However, current benchmarks for evaluating RAG systems suffer from two key deficiencies: (1) they fail to adequately measure LLMs’ capability in handling long-context retrieval due to a lack of datasets that reflect the characteristics of retrieved documents, and (2) they lack a comprehensive evaluation method for assessing LLMs’ ability to generate long-form responses that effectively exploits retrieved information. To address these shortcomings, we introduce the Long2RAG benchmark and the Key Point Recall (KPR) metric. Long2RAG comprises 280 questions spanning 10 domains and across 8 question categories, each associated with 5 retrieved documents with an average length of 2,444 words. KPR evaluates the extent to which LLMs incorporate key points extracted from the retrieved documents into their generated responses, providing a more nuanced assessment of their ability to exploit retrieved information.
- Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model EvaluatorsYinhong Liu*, Han Zhou*, Zhijiang Guo, Ehsan Shareghi, Ivan Vulic, Anna Korhonen, and Nigel CollierIn COLM, 2024
Large Language Models (LLMs) have demonstrated promising capabilities as automatic evaluators in assessing the quality of generated natural language. However, LLMs still exhibit biases in evaluation and often struggle to generate coherent evaluations that align with human assessments. In this work, we first conduct a systematic study of the misalignment between LLM evaluators and human judgement, revealing that existing calibration methods aimed at mitigating biases are insufficient for effectively aligning LLM evaluators. Inspired by the use of preference data in RLHF, we formulate the evaluation as a ranking problem and introduce Pairwise-preference Search (PairS), an uncertainty-guided search method that employs LLMs to conduct pairwise comparisons and efficiently ranks candidate texts. PairS achieves state-of-the-art performance on representative evaluation tasks and demonstrates significant improvements over direct scoring. Furthermore, we provide insights into the role of pairwise preference in quantifying the transitivity of LLMs and demonstrate how PairS benefits from calibration.
- Learning From Correctness Without Prompting Makes LLM Efficient ReasonerYuxuan Yao*, Han Wu*, Zhijiang Guo†, Biyan Zhou, Jiahui Gao, Sichun Luo, Hanxu Hou, Xiaojin Fu, and Linqi Song†In COLM, 2024
Large language models (LLMs) have demonstrated outstanding performance across various tasks, yet they still exhibit limitations such as hallucination, unfaithful reasoning, and toxic content. One potential approach to mitigate these issues is learning from human or external feedback (e.g. tools). In this paper, we introduce an intrinsic self-correct reasoning framework for LLMs that eliminates the need for human feedback, external tools, and handcraft prompts. The proposed framework, based on a multi-step reasoning paradigm \textbfLearning from \textbfCorrectness (\textscLeCo), improves reasoning performance without needing to learn from errors. This paradigm prioritizes learning from correct reasoning steps, and a unique method to measure confidence for each reasoning step based on generation logits. Experimental results across various multi-step reasoning tasks demonstrate the effectiveness of the framework in improving reasoning performance with reduced token consumption.
- ProxyQA: An Alternative Framework for Evaluating Long-Form Text Generation with Large Language ModelsHaochen Tan*, Zhijiang Guo*, Zhan Shi, Lu Xu, Zhili Liu, Yunlong Feng, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and Linqi Song†In ACL, 2024
Large Language Models (LLMs) have succeeded remarkably in understanding long-form contents. However, exploring their capability for generating long-form contents, such as reports and articles, has been relatively unexplored and inadequately assessed by existing benchmarks. The prevalent evaluation methods, which predominantly rely on crowdsourcing, are recognized for their labor-intensive nature and lack of efficiency, whereas automated metrics, such as the ROUGE score, demonstrate discordance with human judgment criteria. In this paper, we propose ProxyQA, an innovative framework dedicated to assessing long-text generation. ProxyQA comprises in-depth human-curated meta-questions spanning various domains, each accompanied by specific proxy-questions with pre-annotated answers. LLMs are tasked to generate extensive content in response to these meta-questions, by engaging an evaluator and incorporating the generated texts as contextual background, ProxyQA assesses the generated content’s quality through the evaluator’s accuracy in addressing the proxy-questions. We examine multiple LLMs, emphasizing ProxyQA’s demanding nature as a high-quality assessment tool. Human evaluation demonstrates that the proxy-question method is notably self-consistent and aligns closely with human evaluative standards. The dataset and leaderboard is available at \urlhttps://proxy-qa.com.
- Evaluating Robustness of Generative Search Engine on Adversarial Factual QuestionsXuming Hu*, Xiaochuan Li*, Junzhe Chen, Yinghui Li, Yangning Li, Xiaoguang Li, Yasheng Wang, Qun Liu, Lijie Wen, Philip S. Yu, and Zhijiang Guo†In Findings of ACL, 2024
Generative search engines have the potential to transform how people seek information online, but generated responses from existing large language models (LLMs)-backed generative search engines may not always be accurate. Nonetheless, retrieval-augmented generation exacerbates safety concerns, since adversaries may successfully evade the entire system by subtly manipulating the most vulnerable part of a claim. To this end, we propose evaluating the robustness of generative search engines in the realistic and high-risk setting, where adversaries have only black-box system access and seek to deceive the model into returning incorrect responses. Through a comprehensive human evaluation of various generative search engines, such as Bing Chat, PerplexityAI, and YouChat across diverse queries, we demonstrate the effectiveness of adversarial factual questions in inducing incorrect responses. Moreover, retrieval-augmented generation exhibits a higher susceptibility to factual errors compared to LLMs without retrieval. These findings highlight the potential security risks of these systems and emphasize the need for rigorous evaluation before deployment.
- DQ-LoRe: Dual Queries with Low Rank Approximation Re-ranking for In-Context LearningJing Xiong*, Zixuan Li*, Chuanyang Zheng, Zhijiang Guo†, Yichun Yin, Enze Xie, Zhicheng Yang, Qingxing Cao, Haiming Wang, Xiongwei Han, Jing Tang, Chengming Li, and Xiaodan Liang†In ICLR, 2024
Recent advances in natural language processing, primarily propelled by Large Language Models (LLMs), have showcased their remarkable capabilities grounded in in-context learning. A promising avenue for guiding LLMs in intricate reasoning tasks involves the utilization of intermediate reasoning steps within the Chain-of-Thought (CoT) paradigm. Nevertheless, the central challenge lies in the effective selection of exemplars for facilitating in-context learning. In this study, we introduce a framework that leverages Dual Queries and Low-rank approximation Re-ranking (DQ-LoRe) to automatically select exemplars for in-context learning. Dual Queries first query LLM to obtain LLM-generated knowledge such as CoT, then query the retriever to obtain the final exemplars via both question and the knowledge. Moreover, for the second query, LoRe employs dimensionality reduction techniques to refine exemplar selection, ensuring close alignment with the input question’s knowledge. Through extensive experiments, we demonstrate that DQ-LoRe significantly outperforms prior state-of-the-art methods in the automatic selection of exemplars for GPT-4, enhancing performance from 92.5% to 94.2%. Our comprehensive analysis further reveals that DQ-LoRe consistently outperforms retrieval-based approaches in terms of both performance and adaptability, especially in scenarios characterized by distribution shifts. DQ-LoRe pushes the boundary of in-context learning and opens up new avenues for addressing complex reasoning challenges.
- Do Large Language Models Know about Facts?Xuming Hu*, Junzhe Chen*, Xiaochuan Li*, Yufei Guo, Lijie Wen†, Philip S. Yu, and Zhijiang Guo†In ICLR (Spotlight), 2024
Large language models (LLMs) have recently driven striking performance improvements across a range of natural language processing tasks. The factual knowledge acquired during pretraining and instruction tuning can be useful in various downstream tasks, such as question answering, and language generation. Unlike conventional Knowledge Bases (KBs) that explicitly store factual knowledge, LLMs implicitly store facts in their parameters. Content generated by the LLMs can often exhibit inaccuracies or deviations from the truth, due to facts that can be incorrectly induced or become obsolete over time. To this end, we aim to explore the extent and scope of factual knowledge within LLMs by designing the benchmark Pinocchio. Pinocchio contains 20K diverse factual questions that span different sources, timelines, domains, regions, and languages. Furthermore, we investigate whether LLMs can compose multiple facts, update factual knowledge temporally, reason over multiple pieces of facts, identify subtle factual differences, and resist adversarial examples. Extensive experiments on different sizes and types of LLMs show that existing LLMs still lack factual knowledge and suffer from various spurious correlations. We believe this is a critical bottleneck for realizing trustworthy artificial intelligence. The dataset Pinocchio and our codes are publicly available at: https://github.com/THU-BPM/Pinocchio.
- Towards Human-aligned Evaluation for Linear Programming Word ProblemsLinzi Xing*, Xinglu Wang*, Yuxi Feng, Zhenan Fan, Jing Xiong, Zhijiang Guo, Xiaojin Fu, Rindranirina Ramamonjison, Mahdi Mostajabdaveh, Xiongwei Han, Zirui Zhou, and Yong ZhangIn COLING, 2024
Math Word Problem (MWP) is a crucial NLP task aimed at providing solutions for given mathematical descriptions. A notable sub-category of MWP is the Linear Programming Word Problem (LPWP), which holds significant relevance in real-world decision-making and operations research. While the recent rise of generative large language models (LLMs) has brought more advanced solutions to LPWPs, existing evaluation methodologies for this task still diverge from human judgment and face challenges in recognizing mathematically equivalent answers. In this paper, we introduce a novel evaluation metric rooted in graph edit distance, featuring benefits such as permutation invariance and more accurate program equivalence identification. Human evaluations empirically validate the superior efficacy of our proposed metric when particularly assessing LLM-based solutions for LPWP.
- YODA: Teacher-Student Progressive Learning for Language ModelsJianqiao Lu*, Wanjun Zhong*, Yufei Wang, Zhijiang Guo, Qi Zhu, Wenyong Huang, Yanlin Wang, Fei Mi, Baojun Wang, Yasheng Wang, Lifeng Shang, Xin Jiang, and Qun LiuIn ArXiv, 2024
Although large language models (LLMs) have demonstrated adeptness in a range of tasks, they still lag behind human learning efficiency. This disparity is often linked to the inherent human capacity to learn from basic examples, gradually generalize and handle more complex problems, and refine their skills with continuous feedback. Inspired by this, this paper introduces YODA, a novel teacher-student progressive learning framework that emulates the teacher-student education process to improve the efficacy of model fine-tuning. The framework operates on an interactive \textitbasic-generalized-harder loop. The teacher agent provides tailored feedback on the student’s answers, and systematically organizes the education process. This process unfolds by teaching the student basic examples, reinforcing understanding through generalized questions, and then enhancing learning by posing questions with progressively enhanced complexity. With the teacher’s guidance, the student learns to iteratively refine its answer with feedback, and forms a robust and comprehensive understanding of the posed questions. The systematic procedural data, which reflects the progressive learning process of humans, is then utilized for model training. Taking math reasoning as a testbed, experiments show that training LLaMA2 with data from YODA improves SFT with significant performance gain (+17.01% on GSM8K and +9.98% on MATH). In addition, we find that training with curriculum learning further improves learning robustness.


















2023
- AVeriTeC: A Dataset for Real-world Claim Verification with Evidence from the WebMichael Schlichtkrull*, Zhijiang Guo*, and Andreas VlachosIn NeurIPS, 2023
Existing datasets for automated fact-checking have substantial limitations, such as relying on artificial claims, lacking annotations for evidence and intermediate reasoning, or including evidence published after the claim. In this paper we introduce AVeriTeC, a new dataset of 4,568 real-world claims covering fact-checks by 50 different organizations. Each claim is annotated with question-answer pairs supported by evidence available online, as well as textual justifications explaining how the evidence combines to produce a verdict. Through a multi-round annotation process, we avoid common pitfalls including context dependence, evidence insufficiency, and temporal leakage, and reach a substantial inter-annotator agreement of κ=0.619 on verdicts. We develop a baseline as well as an evaluation scheme for verifying claims through several question-answering steps against the open web.
- Multimodal Automated Fact-Checking: A SurveyMubashara Akhtar, M. Schlichtkrull, Zhijiang Guo, Oana Cocarascu, Elena Paslaru Bontas Simperl, and Andreas VlachosIn Findings of EMNLP, 2023
Misinformation is often conveyed in multiple modalities, e.g. a miscaptioned image. Multimodal misinformation is perceived as more credible by humans, and spreads faster than its text-only counterparts. While an increasing body of research investigates automated fact-checking (AFC), previous surveys mostly focus on text. In this survey, we conceptualise a framework for AFC including subtasks unique to multimodal misinformation. Furthermore, we discuss related terms used in different communities and map them to our framework. We focus on four modalities prevalent in real-world fact-checking: text, image, audio, and video. We survey benchmarks and models, and discuss limitations and promising directions for future research
- TRIGO: Benchmarking Formal Mathematical Proof Reduction for Generative Language ModelsJing Xiong, Jianhao Shen, Ye Yuan, Haiming Wang, Yichun Yin, Zhengying Liu, Lin Li, Zhijiang Guo, Qingxing Cao, Yinya Huang, Chuanyang Zheng, Xiaodan Liang, Ming Zhang, and Qun LiuIn EMNLP, 2023
Automated theorem proving (ATP) has become an appealing domain for exploring the reasoning ability of the recent successful generative language models. However, current ATP benchmarks mainly focus on symbolic inference, but rarely involve the understanding of complex number combination reasoning. In this work, we propose TRIGO, an ATP benchmark that not only requires a model to reduce a trigonometric expression with step-by-step proofs but also evaluates a generative LM’s reasoning ability on formulas and its capability to manipulate, group, and factor number terms. We gather trigonometric expressions and their reduced forms from the web, annotate the simplification process manually, and translate it into the Lean formal language system. We then automatically generate additional examples from the annotated samples to expand the dataset. Furthermore, we develop an automatic generator based on Lean-Gym to create dataset splits of varying difficulties and distributions in order to thoroughly analyze the model’s generalization ability. Our extensive experiments show our proposed TRIGO poses a new challenge for advanced generative LM’s including GPT-4 which is pre-trained on a considerable amount of open-source formal theorem-proving language data, and provide a new tool to study the generative LM’s ability on both formal and mathematical reasoning.
- Multimodal Relation Extraction with Cross-Modal Retrieval and SynthesisXuming Hu*, Zhijiang Guo*, Zhiyang Teng, Irwin King, and Philip S. YuIn ACL, 2023
Multimodal relation extraction (MRE) is the task of identifying the semantic relationships between two entities based on the context of the sentence image pair. Existing retrieval-augmented approaches mainly focused on modeling the retrieved textual knowledge, but this may not be able to accurately identify complex relations. To improve the prediction, this research proposes to retrieve textual and visual evidence based on the object, sentence, and whole image. We further develop a novel approach to synthesize the object-level, image-level, and sentence-level information for better reasoning between the same and different modalities. Extensive experiments and analyses show that the proposed method is able to effectively select and compare evidence across modalities and significantly outperforms state-of-the-art models.
- MR2: A Benchmark for Multimodal Retrieval-Augmented Rumor Detection in Social MediaXuming Hu*, Zhijiang Guo*, Junzhe Chen, Lijie Wen, and Philip S. YuIn SIGIR, 2023
As social media platforms are evolving from text-based forums into multi-modal environments, the nature of misinformation in social media is also transforming accordingly. Misinformation spreaders have recently targeted contextual connections between the modalities e.g., text and image. However, existing datasets for rumor detection mainly focus on a single modality i.e., text. To bridge this gap, we construct MR2, a multimodal multilingual retrieval-augmented dataset for rumor detection. The dataset covers rumors with images and texts, and provides evidence from both modalities that are retrieved from the Internet. Further, we develop established baselines and conduct a detailed analysis of the systems evaluated on the dataset. Extensive experiments show that MR2 will provide a challenging testbed for developing rumor detection systems designed to retrieve and reason over social media posts. Source code and data are available at: https://github.com/THU-BPM/MR2.
- Read it Twice: Towards Faithfully Interpretable Fact Verification by Revisiting EvidenceXuming Hu, Zhaochen Hong, Zhijiang Guo, Lijie Wen, and Philip S. YuIn SIGIR, 2023
Real-world fact verification task aims to verify the factuality of a claim by retrieving evidence from the source document. The quality of the retrieved evidence plays an important role in claim verification. Ideally, the retrieved evidence should be faithful (reflecting the model’s decision-making process in claim verification) and plausible (convincing to humans), and can improve the accuracy of verification task. Although existing approaches leverage the similarity measure of semantic or surface form between claims and documents to retrieve evidence, they all rely on certain heuristics that prevent them from satisfying all three requirements. In light of this, we propose a fact verification model named ReRead to retrieve evidence and verify claim that: (1) Train the evidence retriever to obtain interpretable evidence (i.e., faithfulness and plausibility criteria); (2) Train the claim verifier to revisit the evidence retrieved by the optimized evidence retriever to improve the accuracy. The proposed system is able to achieve significant improvements upon best-reported models under different settings.
- Give Me More Details: Improving Fact-Checking with Latent RetrievalXuming Hu*, Zhijiang Guo*, Guan-Huei Wu, Lijie Wen, and Philip S. YuIn ArXiv, 2023
Evidence plays a crucial role in automated fact-checking. When verifying real-world claims, existing fact-checking systems either assume the evidence sentences are given or use the search snippets returned by the search engine. Such methods ignore the challenges of collecting evidence and may not provide sufficient information to verify real-world claims. Aiming at building a better fact-checking system, we propose to incorporate full text from source documents as evidence and introduce two enriched datasets. The first one is a multilingual dataset, while the second one is monolingual (English). We further develop a latent variable model to jointly extract evidence sentences from documents and perform claim verification. Experiments indicate that including source documents can provide sufficient contextual clues even when gold evidence sentences are not annotated. The proposed system is able to achieve significant improvements upon best-reported models under different settings.







2022
- A Survey on Automated Fact-CheckingZhijiang Guo*, Michael Schlichtkrull*, and Andreas VlachosIn TACL, 2022
Fact-checking has become increasingly important due to the speed with which both information and misinformation can spread in the modern media ecosystem. Therefore, researchers have been exploring how fact-checking can be automated, using techniques based on natural language processing, machine learning, knowledge representation, and databases to automatically predict the veracity of claims. In this paper, we survey automated fact-checking stemming from natural language processing, and discuss its connections to related tasks and disciplines. In this process, we present an overview of existing datasets and models, aiming to unify the various definitions given and identify common concepts. Finally, we highlight challenges for future research.
- METS-CoV: A Dataset of Medical Entity and Targeted Sentiment on COVID-19 Related TweetsPeilin Zhou, Zeqiang Wang, Dading Chong, Zhijiang Guo, Yining Hua, Zichang Su, Zhiyang Teng, Jiageng Wu, and Jie YangIn NeurIPS, 2022
The COVID-19 pandemic continues to bring up various topics discussed or debated on social media. In order to explore the impact of pandemics on people’s lives, it is crucial to understand the public’s concerns and attitudes towards pandemic-related entities (e.g., drugs, vaccines) on social media. However, models trained on existing named entity recognition (NER) or targeted sentiment analysis (TSA) datasets have limited ability to understand COVID-19-related social media texts because these datasets are not designed or annotated from a medical perspective. This paper releases METS-CoV, a dataset containing medical entities and targeted sentiments from COVID-19-related tweets. METS-CoV contains 10,000 tweets with 7 types of entities, including 4 medical entity types (Disease, Drug, Symptom, and Vaccine) and 3 general entity types (Person, Location, and Organization). To further investigate tweet users’ attitudes toward specific entities, 4 types of entities (Person, Organization, Drug, and Vaccine) are selected and annotated with user sentiments, resulting in a targeted sentiment dataset with 9,101 entities (in 5,278 tweets). To the best of our knowledge, METS-CoV is the first dataset to collect medical entities and corresponding sentiments of COVID-19-related tweets. We benchmark the performance of classical machine learning models and state-of-the-art deep learning models on NER and TSA tasks with extensive experiments. Results show that the dataset has vast room for improvement for both NER and TSA tasks. METS-CoV is an important resource for developing better medical social media tools and facilitating computational social science research, especially in epidemiology. Our data, annotation guidelines, benchmark models, and source code are publicly available (this https URL) to ensure reproducibility.
- Scene Graph Modification as Incremental Structure ExpandingXuming Hu*, Zhijiang Guo*, Yuwei Fu, Lijie Wen, and Philip S. YuIn COLING, 2022
A scene graph is a semantic representation that expresses the objects, attributes, and relationships between objects in a scene. Scene graphs play an important role in many cross modality tasks, as they are able to capture the interactions between images and texts. In this paper, we focus on scene graph modification (SGM), where the system is required to learn how to update an existing scene graph based on a natural language query. Unlike previous approaches that rebuilt the entire scene graph, we frame SGM as a graph expansion task by introducing the incremental structure expanding (ISE). ISE constructs the target graph by incrementally expanding the source graph without changing the unmodified structure. Based on ISE, we further propose a model that iterates between nodes prediction and edges prediction, inferring more accurate and harmonious expansion decisions progressively. In addition, we construct a challenging dataset that contains more complicated queries and larger scene graphs than existing datasets. Experiments on four benchmarks demonstrate the effectiveness of our approach, which surpasses the previous state-of-the-art model by large margins.
- CHEF: A Pilot Chinese Dataset for Evidence-Based Fact-CheckingXuming Hu*, Zhijiang Guo*, Guanyu Wu, Aiwei Liu, Lijie Wen, and Philip S. YuIn NAACL, 2022
The explosion of misinformation spreading in the media ecosystem urges for automated fact-checking. While misinformation spans both geographic and linguistic boundaries, most work in the field has focused on English. Datasets and tools available in other languages, such as Chinese, are limited. In order to bridge this gap, we construct CHEF, the first CHinese Evidence-based Fact-checking dataset of 10K real-world claims. The dataset covers multiple domains, ranging from politics to public health, and provides annotated evidence retrieved from the Internet. Further, we develop established baselines and a novel approach that is able to model the evidence retrieval as a latent variable, allowing jointly training with the veracity prediction model in an end-to-end fashion. Extensive experiments show that CHEF will provide a challenging testbed for the development of fact-checking systems designed to retrieve and reason over non-English claims.
- GRATIS: Deep Learning Graph Representation with Task-specific Topology and Multi-dimensional Edge FeaturesSiyang Song, Yuxin Song, Cheng Luo, Zhiyuan Song, Selim Kuzucu, Xi Jia, Zhijiang Guo, Weicheng Xie, Linlin Shen, and Hatice Gunes2022
Graph is powerful for representing various types of real-world data. The topology (edges’ presence) and edges’ features of a graph decides the message passing mechanism among vertices within the graph. While most existing approaches only manually define a single-value edge to describe the connectivity or strength of association between a pair of vertices, task-specific and crucial relationship cues may be disregarded by such manually defined topology and single-value edge features. In this paper, we propose the first general graph representation learning framework (called GRATIS) which can generate a strong graph representation with a task-specific topology and task-specific multi-dimensional edge features from any arbitrary input. To learn each edge’s presence and multi-dimensional feature, our framework takes both of the corresponding vertices pair and their global contextual information into consideration, enabling the generated graph representation to have a globally optimal message passing mechanism for different down-stream tasks. The principled investigation results achieved for various graph analysis tasks on 11 graph and non-graph datasets show that our GRATIS can not only largely enhance pre-defined graphs but also learns a strong graph representation for non-graph data, with clear performance improvements on all tasks. In particular, the learned topology and multi-dimensional edge features provide complementary task-related cues for graph analysis tasks. Our framework is effective, robust and flexible, and is a plug-and-play module that can be combined with different backbones and Graph Neural Networks (GNNs) to generate a task-specific graph representation from various graph and non-graph data.





2021
- FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured informationRami Aly, Zhijiang Guo, M. Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit MittalIn NeurIPS, 2021
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
- Uncovering Main Causalities for Long-tailed Information ExtractionGuoshun Nan, Jiaqi Zeng, Rui Qiao, Zhijiang Guo, and Wei LuIn EMNLP, 2021
Information Extraction (IE) aims to extract structural information from unstructured texts. In practice, long-tailed distributions caused by the selection bias of a dataset, may lead to incorrect correlations, also known as spurious correlations, between entities and labels in the conventional likelihood models. This motivates us to propose counterfactual IE (CFIE), a novel framework that aims to uncover the main causalities behind data in the view of causal inference. Specifically, 1) we first introduce a unified structural causal model (SCM) for various IE tasks, describing the relationships among variables; 2) with our SCM, we then generate counterfactuals based on an explicit language structure to better calculate the direct causal effect during the inference stage; 3) we further propose a novel debiasing approach to yield more robust predictions. Experiments on three IE tasks across five public datasets show the effectiveness of our CFIE model in mitigating the spurious correlation issues.


2020
- Lightweight, Dynamic Graph Convolutional Networks for AMR-to-Text GenerationYan Zhang*, Zhijiang Guo*, Zhiyang Teng, Wei Lu, Shay B. Cohen, Zuozhu Liu, and Lidong BingIn EMNLP, 2020
AMR-to-text generation is used to transduce Abstract Meaning Representation structures (AMR) into text. A key challenge in this task is to efficiently learn effective graph representations. Previously, Graph Convolution Networks (GCNs) were used to encode input AMRs, however, vanilla GCNs are not able to capture non-local information and additionally, they follow a local (first-order) information aggregation scheme. To account for these issues, larger and deeper GCN models are required to capture more complex interactions. In this paper, we introduce a dynamic fusion mechanism, proposing Lightweight Dynamic Graph Convolutional Networks (LDGCNs) that capture richer non-local interactions by synthesizing higher order information from the input graphs. We further develop two novel parameter saving strategies based on the group graph convolutions and weight tied convolutions to reduce memory usage and model complexity. With the help of these strategies, we are able to train a model with fewer parameters while maintaining the model capacity. Experiments demonstrate that LDGCNs outperform state-of-the-art models on two benchmark datasets for AMR-to-text generation with significantly fewer parameters.
- Learning Latent Forests for Medical Relation ExtractionZhijiang Guo*, Guoshun Nan*, Wei Lu, and Shay B. CohenIn IJCAI, 2020
The goal of medical relation extraction is to detect relations among entities, such as genes, mutations and drugs in medical texts. Dependency tree structures have been proven useful for this task. Existing approaches to such relation extraction leverage off-the-shelf dependency parsers to obtain a syntactic tree or forest for the text. However, for the medical domain, low parsing accuracy may lead to error propagation downstream the relation extraction pipeline. In this work, we propose a novel model which treats the dependency structure as a latent variable and induces it from the unstructured text in an end-to-end fashion. Our model can be understood as composing task-specific dependency forests that capture non-local interactions for better relation extraction. Extensive results on four datasets show that our model is able to significantly outperform state-of-the-art systems without relying on any direct tree supervision or pre-training.
- Reasoning with Latent Structure Refinement for Document-Level Relation ExtractionGuoshun Nan*, Zhijiang Guo*, Ivan Sekulic, and Wei LuIn ACL, 2020
Document-level relation extraction requires integrating information within and across multiple sentences of a document and capturing complex interactions between inter-sentence entities. However, effective aggregation of relevant information in the document remains a challenging research question. Existing approaches construct static document-level graphs based on syntactic trees, co-references or heuristics from the unstructured text to model the dependencies. Unlike previous methods that may not be able to capture rich non-local interactions for inference, we propose a novel model that empowers the relational reasoning across sentences by automatically inducing the latent document-level graph. We further develop a refinement strategy, which enables the model to incrementally aggregate relevant information for multi-hop reasoning. Specifically, our model achieves an F1 score of 59.05 on a large-scale document-level dataset (DocRED), significantly improving over the previous results, and also yields new state-of-the-art results on the CDR and GDA dataset. Furthermore, extensive analyses show that the model is able to discover more accurate inter-sentence relations.



2019
- Attention Guided Graph Convolutional Networks for Relation ExtractionZhijiang Guo*, Yan Zhang*, and Wei LuIn ACL, 2019
Dependency trees convey rich structural information that is proven useful for extracting relations among entities in text. However, how to effectively make use of relevant information while ignoring irrelevant information from the dependency trees remains a challenging research question. Existing approaches employing rule based hard-pruning strategies for selecting relevant partial dependency structures may not always yield optimal results. In this work, we propose Attention Guided Graph Convolutional Networks (AGGCNs), a novel model which directly takes full dependency trees as inputs. Our model can be understood as a soft-pruning approach that automatically learns how to selectively attend to the relevant sub-structures useful for the relation extraction task. Extensive results on various tasks including cross-sentence n-ary relation extraction and large-scale sentence-level relation extraction show that our model is able to better leverage the structural information of the full dependency trees, giving significantly better results than previous approaches.
- Densely Connected Graph Convolutional Networks for Graph-to-Sequence LearningZhijiang Guo*, Yan Zhang*, Zhiyang Teng, and Wei LuIn TACL, 2019
We focus on graph-to-sequence learning, which can be framed as transducing graph structures to sequences for text generation. To capture structural information associated with graphs, we investigate the problem of encoding graphs using graph convolutional networks (GCNs). Unlike various existing approaches where shallow architectures were used for capturing local structural information only, we introduce a dense connection strategy, proposing a novel Densely Connected Graph Convolutional Networks (DCGCNs). Such a deep architecture is able to integrate both local and non-local features to learn a better structural representation of a graph. Our model outperforms the state-of-the-art neural models significantly on AMRto-text generation and syntax-based neural machine translation.


2018
- Better Transition-Based AMR Parsing with a Refined Search SpaceZhijiang Guo, and Wei LuIn EMNLP, 2018
This paper introduces a simple yet effective transition-based system for Abstract Meaning Representation (AMR) parsing. We argue that a well-defined search space involved in a transition system is crucial for building an effective parser. We propose to conduct the search in a refined search space based on a new compact AMR graph and an improved oracle. Our end-to-end parser achieves the state-of-the-art performance on various datasets with minimal additional information.
